5月242012
0
去年作ったSinatra+Haml+jQuery入門のテンプレ、なにげにしょっちゅうアップデートしている。
内容は↑にも書いてあるがおみくじを引くだけの超単純なアプリだ。
新規プロジェクトを開始する時はコレをcloneして使うので、余計な物を付けない様にしている。
githubのリポジトリはここ https://github.com/shokai/sinatra-template
■使っている部品
今はこういう構成になっている
- Ruby 1.8.7
- Sinatra 1.3
- Haml + sinatra-content-for
- Sass
- jQuery
- foreman
- bundler
master以外のブランチにmongoidとdm-mysqlの2つがある。
それぞれDataMapper+MySQLと、Mongoid+MongoDBをバックエンドにしたやつ。
DataMapper+MySQL版はこんなファイル構成にしている。(Mongoidもほぼ同じ)
.
├── Gemfile # 必要なGEMを書いておくファイル。bundle installで一気にインストールされる。
├── Procfile # webサーバーと同時に起動するプロセスを書いておく
├── README.md
├── bin
│ ├── console.rb # DB接続してModel読み込んだ状態でIRBが起動する
│ ├── db_migrate.rb # DBを初期化するツール
│ └── db_upgrate.rb # model更新した時にDBスキーマを更新するツール
├── bootstrap.rb # これを読み込むとconfig.ymlを読んだりmodels/controllers/hellpersを一括読み込みしたりできる
├── config.ru # RackUp用の設定
├── config.yml # 設定ファイル
├── controllers # sinatraのルーティングメソッドを書いたファイルを入れるディレクトリ
│ ├── css.rb
│ └── main.rb
├── helpers # 便利関数を入れるディレクトリ
│ └── helper.rb
├── inits # DB接続とか、一番最初に実行すべき処理を書く
│ └── db.rb
├── models
│ └── omikuji.rb # DBのQueryとかを集約する
├── public
│ └── js
│ ├── jquery.js
│ └── main.js # index.hamlから読まれるJS
├── sample.config.yml # config.ymlにリネームして使う
└── views
├── index.haml # レイアウト抜きのメインコンテンツ部分
├── layout.haml # レイアウト
└── main.scss # cssのテンプレ
■DataMapperとMySQLを使う
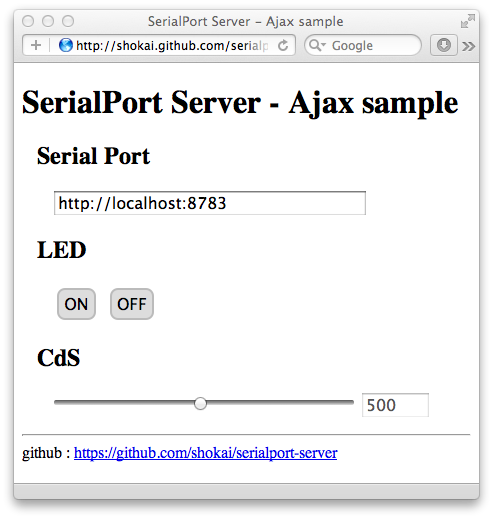
MySQL版はこんなの(デモ)
MySQLのセットアップは以前書いた
この下に書いてある事はREADMEにも書いてある。
cloneしてくる
% git clone git://github.com/shokai/sinatra-template.git
% cd sinatra-template
% git branch -a
% git checkout -b dm-mysql remotes/origin/dm-mysql
設定
% cp sample.config.yml config.ymlconfig.ymlのMySQLのパスワード等を変更する
DB作る。最初のDB作る部分はログインして自分で作らないとならない。
% mysql -u your_name -pDB初期化するけどいいか?と訊かれるのでYesと答えよう。
mysql> create database sinatra_template
% ruby bin/db_migrate.rb
起動
% gem install foreman bundlerhttp://localhost:8080 で起動する。
% bundle install
% foreman start
なんかすごい当たり前の話なんだけど、単純なWebアプリではなく、クローラとか色々と組み合わせたアプリを書くことが多い。
クローラとWebアプリが同じModelを読み込んで、同じ設定ファイルを読んで同じDBに接続するようにすると、綺麗に実装できる。
conosle.rbみたいな書き方をすると良い。
#!/usr/bin/env rubyこれだけでDB接続してModelを読み込めるので、あとは普通に書けばいい。
require 'rubygems'
require 'bundler/setup'
require File.dirname(__FILE__)+'/../bootstrap'
Bootstrap.init :inits, :models
設定ファイル(config.yml)の中身も、main.rbでやっているように
@title = Conf['title']みたいに取り出せる。
result = Conf['omikuji'].choice