1月112016
0
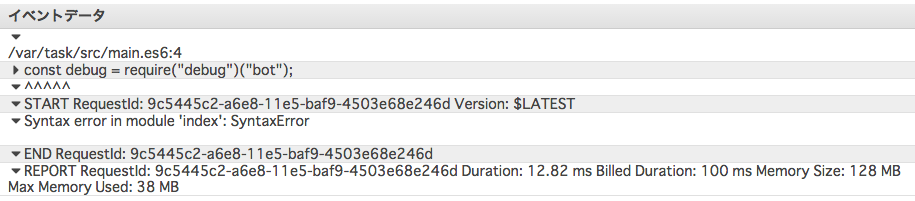
mochaでtestを書く時にitという関数を使うのだが、ifと書き間違えている事に気づかず30分ぐらいハマった。前にも同じ事があったのに30分かかったので、この調子だと何度でもハマる自信がある。
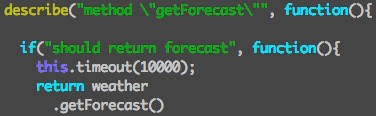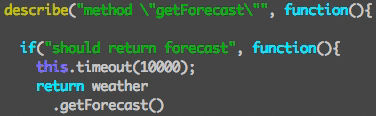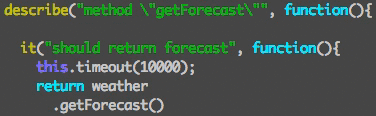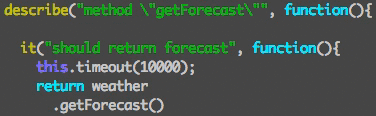
itがifでも文法エラーが起こらないし、そのテストコードの部分が実行されないだけなので気づかない。
シンタックスハイライトされてても文字の色で判別なんて人間には不可能。
間違え探しみたいなデバッグをしたくないからテスト書くのに、そのテスト自体が間違え探しなのはどうなのと思う。
もっと細かく考えると
- if文に定数を渡せるのがおかしい
- カンマ演算子の存在自体が悪い
- itって関数名どうなの
- そもそもtestの中でif文なんて必要ない
というのがある。
eslint-if-in-test作った
テストコードの中でif文を使う理由が思いつかないので、ESLintでなんとかする事にした。ESLintはプラグインを簡単に自作できるのですぐできた。https://www.npmjs.com/package/eslint-plugin-if-in-test
describe()の中でif文を使っていたら警告してくれる

他のソリューション
eslint-if-in-test作っている時にESLint自体のテストがうまく書けなくてtwitterで愚痴っていたら色々教えてもらえた。ESLintには既に色々プラグインがある。
特にno-constant-conditionはif文に定数渡したら警告してくれるので良いなと思った。
というかこっちで十分だと思う。完成してから知った。
ESLintのruleを作る
ESLintのruleの作り方を調べたのでメモしておく。かなり簡単に作れる。まずドキュメントを読んでいくとruleの作り方というのがあるんだけど、ESLintのソースコードの中のlibの下にファイル作ってねとか言われる。
pluginの作り方の方を見たほうが良さそう。
ESLintのpluginを作る
pluginの中にruleをまとめて、npmとして公開できる。yeomanにテンプレートがある。
% mkdir eslint-plugin-if-in-test
% cd eslint-plugin-if-in-test/
% npm i yo generator-eslint -g
% yo eslint:plugin
(質問に答える)
% npm i
テンプレができる
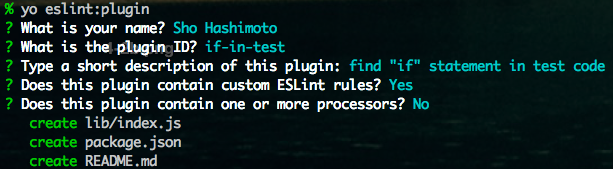
最終的にこうなった。 lib/rules/if.js と tests/lib/rules/test_if.js を自分で書いた。
├── README.md
├── lib
│ ├── index.js
│ └── rules
│ └── if.js
├── package.json
└── tests
└── lib
└── rules
└── test_if.js
罠もあった。
作られたテンプレのpackage.jsonで指定されているESLintが1.2.0と古い物なので最新(1.10)に直した。
あとlib/index.jsのrequireindex npmの呼び出し方が間違ってて動かないので自分でrequireした。
この辺は後でプルリクしたい。
pluginにRuleを書く
ESLintはJavaScriptを解析してAST(抽象構文木)を作って、それを解析して警告などを出す。ASTのnodeのtypeをruleで指定しておくとそれを受け取れるので、適当に解析してエラーがあったらreportを返せばいい。
ASTはAST explorerでもみれる。
とりあえず対象ファイルがtestディレクトリの中にあるかをcontextで確認して、if文があったらcontext.reportするようにした。
lib/rules/if.js
var path = require("path");
var chalk = require("chalk");
module.exports = function(context){
// テストコードのディレクトリ内だけ判定
var testDir = path.resolve(context.options[0].directory);
var testDirPattern = new RegExp("^" + testDir + "/");
if(!testDirPattern.test(context.getFilename())) return {};
// "if" statement in test-code
return {
"IfStatement": function(node){
var code = context.getSourceCode().getText(node).slice(0, 15) + "~~~";
context.report({
node: node,
message: code.replace(/^if/, chalk.bold.underline('if'))
+ " is probably typo of "
+ code.replace(/^if/, chalk.bold.underline('it'))
});
}
}
};
// .eslintのバリデータ JSON-Schema
module.exports.schema = [
{
type: "object",
properties: {
directory: { // directoryプロパティがstring型で必須
type: "string"
}
},
additionalProperties: false
}
];
ESLintが出すnodeの種類はestree/spec.mdにリストがある。
実装サイズの小さそうなpluginをnpmjs.comで探して参考にもした。
lodashをrequireする時にlodash全体を読み込んでいたら警告するのとか
https://github.com/eslint-plugins/eslint-plugin-lodash/blob/master/src/rules/import.js
console.logを使っていたら警告とか
https://github.com/joeybaker/eslint-plugin-no-console-log/blob/master/lib/rules/no-console-log.js
pluginを動かす
作ったpluginが動くかどうかは、mochaでテスト書いてる適当なアプリの中にインストールすればいい。開発中のnpmを読み込む場合はnode_modules/内にシンボリックリンク貼るといい。
% cd node_modules/たぶんnpm linkを使っても良さそうだけどやったことない。
% ln -s ../../eslint-if-in-test eslint-if-in-test
.eslintrc に設定する。module.exports.schemaで指定したオプションで、test/をdirectoryとして渡す。
{
"plugins":[
"if-in-test"
],
"rules":{
"if-in-test/if": [1, {"directory": "test"}]
}
}
if-in-testのルールを読み込んでlintできる。
% eslint test/*.js
describeの中のif文のみ警告する
もっとまともに書く。itはdescribeの中でしか使わない。
ESLintのルールを自作しよう! – Yahoo! JAPAN Tech Blog
を読んでいたら、node typeの末尾に:exitを付けたらtree walkして出る時に拾える事を知った。
nodeへの出入りをカウントする事でとても簡単にifがdescribeの中にあるかどうか判定できた。
lib/rules/if.js
var path = require("path");
var chalk = require("chalk");
module.exports = function(context){
// テストコードのディレクトリ内だけ判定
var testDir = path.resolve(context.options[0].directory);
var testDirPattern = new RegExp("^" + testDir + "/");
if(!testDirPattern.test(context.getFilename())) return {};
var describeCallCount = 0; // describe呼び出しの中にいるかカウントする
return {
"CallExpression": function(node){ // 何かの関数呼び出しに入った
if(node.callee.name === "describe") describeCallCount += 1;
},
"CallExpression:exit": function(node){ // 出た
if(node.callee.name === "describe") describeCallCount -= 1;
},
"IfStatement": function(node){
if(describeCallCount < 1) return;
// describe()の中の時
var code = context.getSourceCode().getText(node).slice(0, 15) + "~~~";
context.report({
node: node,
message: code.replace(/^if/, chalk.bold.underline('if'))
+ " is probably typo of "
+ code.replace(/^if/, chalk.bold.underline('it'))
});
}
}
};
// validator for .eslint
module.exports.schema = [
{
type: "object",
properties: {
directory: {
type: "string"
}
},
additionalProperties: false
}
];
最初はnode.parentを辿って確認してたんだけど、カウントする方が楽だったのでやめた。
ESLint Ruleのtestを書く
ルールのテストも書ける。
http://eslint.org/docs/developer-guide/working-with-plugins#testing
http://eslint.org/docs/developer-guide/working-with-rules#rule-unit-tests
ESLint組み込みのRuleTesterにvalidとinvalidを渡す
tests/lib/rules/test_if.js
var path = require("path");
var rule = require("../../../lib/rules/if")
var RuleTester = require("eslint").RuleTester;
var ruleTester = new RuleTester();
ruleTester.run("rule \"if\"", rule, {
valid: [
{
code: "if(true){ }",
options: [{directory: "test"}],
filename: path.resolve("test/foo/bar/baz.js")
},
],
invalid: [
{
code: "describe('foo', function(){ if('should ~~', function(){ }); }); // \"if\" in describe",
options: [{directory: "test"}],
errors: [{message: null, type: "IfStatement"}],
filename: path.resolve("test/foo/bar/baz.js")
}
]
});
mochaでテストできる
% mocha tests/lib/rules/test_*.js
Testerにfilenameを渡せる事を教えてもらえてテストが実現できた。
@shokai なるほど。 Tester からファイル名を渡すことができます。こちらを参考に: https://t.co/Cw25SAxoXW
— Toru Nagashima (@mysticatea) January 9, 2016
 eventはevent.cmdを参照してchild_process.execするのに使われているが、これはActionsのドロップダウンメニューからJSON形式で編集できる。
eventはevent.cmdを参照してchild_process.execするのに使われているが、これはActionsのドロップダウンメニューからJSON形式で編集できる。