tesselのaudioモジュールを使うとLine出力でスピーカーに接続し、音がだせる。
再生できるのはmp3とwavファイル。
普通のmp3を再生
こんなコードで再生できる。tesselで実行するjsファイルと同じ階層に”cabbage.mp3″をを置いたら、fs.readFileSyncで読めた。実装をちゃんと追ってないから詳細はわからないがファイルシステムがあるらしい。
tessel-study/audio-play-mp3 at master · shokai/tessel-study
var tessel = require('tessel');
var fs = require('fs');
var audio = require('audio-vs1053b').use(tessel.port['A']);
audio.on('ready', function(){
console.log('audio ready');
audio.setVolume(20, function(err){
if(err) return console.error(err);
var data = fs.readFileSync('cabbage.mp3');
setInterval(function(){
audio.play(data, function(err){
if(err) return console.error(err);
console.log('audio done');
});
}, 2000);
});
});
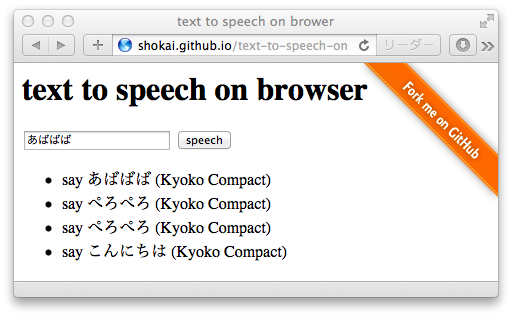
日本語の音声を再生
強引だけどgoogle翻訳のmp3を取得して再生できた。ただし再生まで10秒ぐらいかかる。
tessel-study/audio-google-say at master · shokai/tessel-study
var tessel = require('tessel');
var fs = require('fs');
var stream = require('stream');
var request = require('request');
var wifi = require('wifi-cc3000');
var audio = require('audio-vs1053b').use(tessel.port['A']);
var led_green = tessel.led[0].output(1);
setInterval(function(){
led_green.toggle()
}, 200);
var getAudioStream = function(speech_text){
return request.get({
uri: 'http://translate.google.com/translate_tts',
qs: {
q: speech_text,
tl: 'ja'
},
headers: {
'User-Agent': 'Safari/1.0'
}
});
};
var say = function(speech_text){
console.log('say:'+speech_text);
if(!wifi.isConnected()){
console.error('wifi is not connected');
return;
}
var buf = new Buffer(10240);
var offset = 0;
var ws = stream.Writable({decodeStrings: false});
ws._write = function(chunk, enc, next){
if(chunk.length > buf.length - offset){
return next(new Error('buffer over'));
}
buf.write(chunk, offset, buf.length - offset);
offset += chunk.length;
next();
};
var req = getAudioStream(speech_text);
req.pipe(ws);
req.on('end', function(){
audio.play(buf);
});
};
audio.on('ready', function(){
console.log('audio ready');
audio.setVolume(20, function(err){
if(err) return console.error(err);
audio.emit('ready:volume');
});
});
audio.on('ready:volume', function(){
console.log('audio ready:volume');
if(err) return console.error(err);
setInterval(function(){
say('うどん居酒屋 かずどん');
}, 30*1000);
say('焼肉ざんまい');
});
stream
本当はaudio.createPlayStream()を使いたいんだけど、ビミョーに再生できるのに音声の最後が切れてしまう。音声の長さに関係なく、最後が切れる。
getAudioStream("ざんまい").pipe(audio.createAudioStream());
audio.createPlayStreamの実装も見たけど、どうもそっちじゃなくてstreamの実装の方にバグがある気がする。