12月022015
0
BlendMicro npmが自動再接続・複数接続できるようになった
で、BLE Nanoにも接続できるっぽいと書いた。今やってる。
BLENano実機の開発環境が手に入ったのでセットアップしたメモを書いておく。
BLE Nano
写真の上の部分がBLE Nanoで、下はそれにUSBインタフェースを追加するMK20 USBボード。プログラムを書き込む時だけ下が必要で、デプロイする時は上の部分だけで良い。なおBLE Nanoは12ピンでMK20は14ピン、1ピンずつ余るけど差し間違えると死ぬ可能性があるので注意。写真のようにUSBコネクタ側を余らせ、USBコネクタと反対側に白いアンテナとRedBearLabのクママークが来るようにする

BlendMicroとの違い
BLE Nanoと似たものにBlendMicroがあるが、これは普通のAVRマイコンを使ったArduinoにnRF8001というBLEチップを外付けして、その間の通信が簡単にできるArduinoライブラリとセットにしたボード。それに対してBLE NanoはBLEの機能が内蔵されたnRF51822というARM CPUと、電源のレギュレータや無線アンテナなどを1枚の基板に載せたマイコンボード。
ワンチップに全て入っているので、外付けBLEモジュールと通信してるBlendMicroよりもBLEのより細かい機能を扱える。サンプルコードを見るとBLEのCentral(スマホやPC側の動作)として動かす例なんかもあって、だいたい何でもできそう。
またICが1つだけなので消費電力も低いらしく、ボタン電池で動く。
買う
スイッチサイエンスで売ってる。Amazonにもある

開発方法
開発方法は2通りあって、mbedのオンラインコンパイラを使うか、Arduino IDE用のプラグインを入れてArduino風のAPIで開発もできる。Arduino風に開発する方は、digitalWriteやanalogRead等のIO操作やdelay(msec)などのArduino互換の関数があるだけで、BLE操作の部分はふつうにmbedのC++のライブラリをincludeして行うのであまり関係ない気もする。
そして何より、ひとたびBLEを動かし始めたらmainループの中でble.waitForEvent()を呼んで、あとは全てイベント駆動で書かなければならないのでどれだけ既存のArduinoライブラリが動くかわからない。
イベント駆動についてはIntroduction to mbed BLEに書いてあるが、ようするに基本的にTickerという定期的に関数を呼び出してくれるタイマーか、BLEのデータ受信イベント等にコールバック関数を登録してアプリケーションを書く事になり、mainループは使わない。
そう考えるとArduino風に書けるメリットはあんまり無いような??気がしてきたけど、オンラインコンパイラなしで、ネットワークの無い所でも開発できるのでArduino IDE拡張の方が個人的には好きかも。(mbedオンラインコンパイラよりemacsで書いて+GitHubで管理したいし)
mbedオンラインコンパイラで開発する
web上にあるIDEで開発して、コンパイルするとhexバイナリをダウンロードできる。BLENanoをMacにUSB接続すると /Volumes/MBED にマウントされるので、そこにhexファイルをコピーする。BLE Nanoが自動的に再起動して、hexが読み込まれ実行される。
たとえばURI BeaconのチュートリアルにあるBLE_URIBeaconというプログラムを書き込むと、PhysicalWebのURI Beaconが作れる。Androidアプリから見れるはず。
mbedオンラインコンパイラで公開されているプロジェクトは自分のアカウントにforkして読み込んで自由に編集できるので、試してみるとよい。
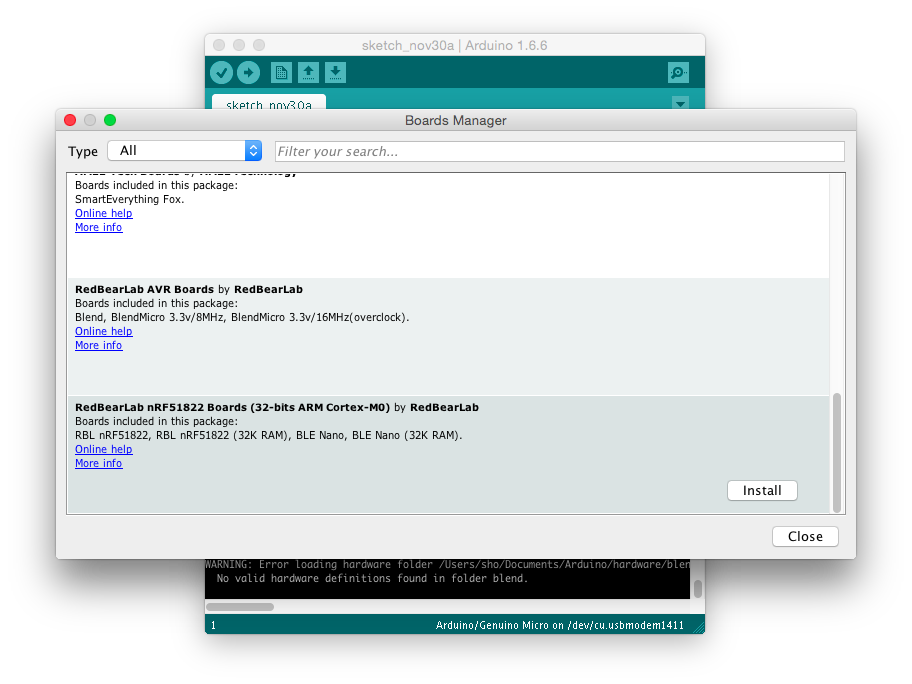
BLE NanoのArduino風開発環境セットアップ
2ステップ必要- BLE NanoをArduino化して
- Arduino IDEにプラグインをインストールする
https://github.com/RedBearLab/nRF51822-Arduino
の説明の方が新しくて正しい。
とくに最近ArduinoはパッケージマネージャがついてBLENanoもそれに乗せて配布されるようになっているので、最新のインストール方法はgithubのREADMEを見たほうが良さそう。