新横浜は新幹線が止まるしイベント施設が複数あるので、土日はなんらかの目的をもって訪れる人が多いみたいでニコニコ笑顔の人が多くて良い。そのかわりイベントの入場前・退場後の時間帯は強烈に混雑して駅に入れなくなる事がまれによくある。
そこでtwitter botにイベント情報を喋らせることにした。毎朝ツイートするので危険を察知できる。
そのうち混雑度を算出する機能も追加したい。あと開場時間も。
ソースコード
https://github.com/shokai/neoyokohama-bot
coを使うと、非同期処理を同期的に書いて順番に実行したり、あるいはasync.jsみたいに同時実行して完了を待ち受けて合流させたりがコールバック地獄を起こさず簡単に書けるので、こういうバッチ処理的な順序が大事な処理は書きやすいだろうなと思って色々試していたらいつの間にかtwitter botになってた。
まず横浜アリーナと日産スタジアムの予定を同時に取得し、Tweetする。Tweetしつつ同時に天気予報を取得する。先のTweetのstatus_idをin_reply_to_status_idにセットしつつ天気予報をTweetする事で連続tweetになる。この間約3秒である。
スクリプトはAWS Lambdaで毎朝1回実行している。AWS Lambdaはメモリ使用量×処理時間で課金されるが、毎日約48MB×3秒で月に4.3GBなので、無料枠の400000GBに十分収まっている。同じようなbotをあと10万個ぐらい無料でデプロイできる。
Lambdaについてぐぐると、最近はPython使ってる記事が多いというかほぼJavaScriptで書いてる記事が無いような?状況だけど、たぶんコールバック地獄がつらいからLambdaに向いてないとか思われてそう。
coでだいたい解決するし、それどころか複数のIO待ちする処理を同時実行する等も書きやすいからJavaScriptいいと思う。
以下、coやLambdaについて忘れないようにメモしておく
async/awaitで非同期処理を同期的に書く
まず最初に、12月半ばごろ、
esnext – Async Functions – Qiitaを見て、非同期処理を同期的に書けるasync/awaitという文法が作られているのだなあと思って調べていた
function foo(wait = 1000){
return new Promise((resolve) => {
console.log(`wait ${wait} msec`);
setTimeout( () => {
resolve(`done waiting ${wait} msec`);
}, wait);
});
}
(async function(){
const result = await foo(1000); // コールバックじゃなくて同期的に呼び出せる
console.log(result);
})();
babelでトランスパイルするとGeneratorを使ってwhileで回して待ち続ける感じになっているみたいだけどよくわからなかった。
regenerator-runtimeが使われている。
coで非同期処理を同期的に書く
そういえばGeneratorで同期的に書けるやつっていうと、
coを使ったことなかったな、と思いだして触りだした。
coもまたPromiseを返す関数を同期的に扱える。
import co from "co"
co(function *(){
const result = yield foo(1000); // 上と同じ関数fooを同期的に呼び出す
console.log(result);
});
async/awaitと似たような感じになる。
coの方はもっと高機能で、Generatorを包んだco自体がPromiseを返すのでさらに別のcoに食わせたりできる。coを使って書いた関数をライブラリとして提供して、それをmainのcoから呼び出して・・・というのを何重もできる。
co.wrap(generator)すると即時実行せずに関数として定義できるのでcallにthisを渡せばES6のclass構文にうまくハマる。
src/yokohama-arena.es6
// 横浜アリーナのイベント情報class
class YokohamaArena{
constructor(){
this.url = "http://www.yokohama-arena.co.jp/event/";
}
getEvents(){ // 全イベント取得
return co.wrap(function *(){
const html = yield this.getHtml(); // 非同期でhtmlを取得
const events = this.parseHtml(html); // parseは同期処理
return events;
}).call(this);
}
getMajorEvents(){ // 設営日を除いたイベント取得
return co.wrap(function *(){
const events = yield this.getEvents();
return events.filter((i) => { return !(/設営日/.test(i.title)) });
}).call(this);
}
getHtml(){
return new Promise((resolve, reject) => {
superagent
.get(this.url)
// (略)
coで複数の非同期処理を同時実行する
上のようにイベント施設ごとのスクレイピングモジュールをそれぞれ作っておいて、coで同時に呼び出す。
yieldにオブジェクトを渡すと全部同時に評価して、完了したら結果をまとめて返してくれる。下の例だとevents.arenaで横浜アリーナのイベント情報が、events.nissanで日産スタジアムの情報が得られる。
src/main.es6
co(function *(){
const events = yield {
arena: arena.getMajorEvents(),
nissan: nissan.getMajorEvents()
};
});
同時実行はyieldに配列を渡してもよい。
ES6の分割代入を使ったら、tweetを投稿しつつ同時に天気予報を取得するのが綺麗に書けた。
const [tweet, forecast] = yield [
twitterClient.update({status: tweetText}),
weather.getForecast()
];
coのエラー処理
co自体がPromiseを返すので、まとめてcatchできる。
co(function *(){
/** なんかエラーが起こりうる処理 **/
}).catch((err) => {
console.error(err.stack || err); // スタックトレースがあればprintする。無ければエラーそのものを
});
Node.jsでAWS Lambdaを書く
AWS Lambdaはアプリケーションのプロセスではなくlambda、つまり関数単位でホスティングしてくれるサービス。AWSにあるDBやqueueなどのサービスにデータが書き込まれたらそれに反応してLambda Functionが起動して小さな仕事をしてすぐ終了するような感じで使われる。functionの起動さえ十分に速ければ、確かにずっとプロセスが起きていてメモリを専有しているような普通の実装よりも効率がいい。
ためしにfunctionを作ってみるとわかりやすい。新規作成するとblueprint(ある程度できてるサンプルコード)から選択させられるので、node-execを選ぶと一番シンプルでいい。
child_processでshellコマンドをexecするサンプルになっている。
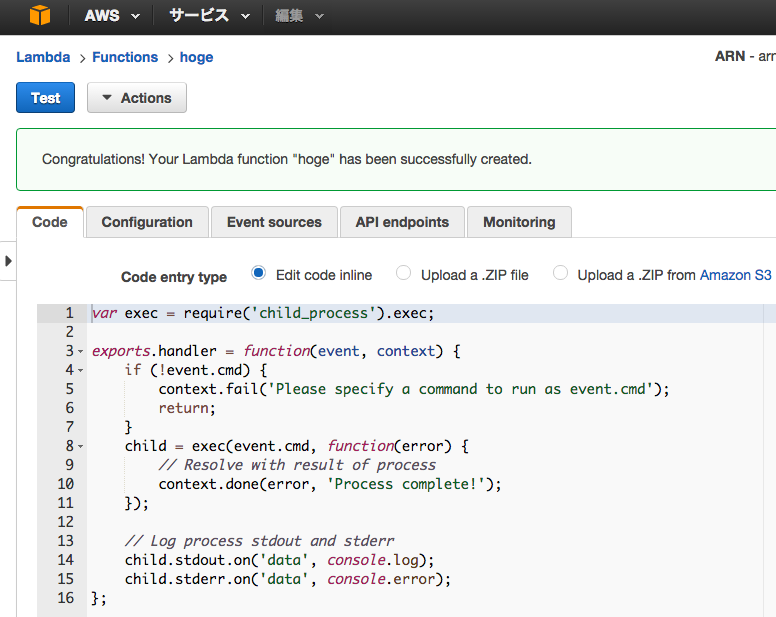
eventはevent.cmdを参照してchild_process.execするのに使われているが、これはActionsのドロップダウンメニューからJSON形式で編集できる。
contextにはawsRequestIdやinvokeidが入っていて、これでAWS上のどういう環境で実行されているかが見れる。ローカルマシンで実行しているかとか判別するのにも使える。
Configurationタブを見ると、index.jsというファイル名とhandlerという関数名が指定されている。
基本形はmodule.exports.handlerを宣言したindex.jsというファイル1つで、これがAWS上でrequireされて呼び出される。
module.exports.handler = function(event, context){
/** なんか処理 **/
context.done(null, "完了");
}
context.doneかcontext.failを呼ばないと設定したtimeout時間まで延々動き続けて課金されるので注意する。
co自身から出るPromiseでエラーをcatchした時も、context.failさせる。
AWS Lambdaでnpmを使う
ファイル単一でformに貼り付けて実行するのではなく、zipで固めてアップロードでもいい。
node_modules/ 以下も一緒にzipすればいい。最大50MBまでいける。
Using Packages and Native nodejs Modules in AWS Lambda | AWS Compute Blog
Lambda上でネイティブのOpenCV拡張を呼ぶために、EC2インスタンス作ってOpenCVをビルドして静的リンクして全部zipで固めている例もある。
このへんは
serverlessを使えば全部CLIでできるみたいだけど、他のAWSの機能を使う予定が無いし生のAWS Lambdaを触ってみたかったので今回はzipでアップロードでやる事にした。
AWS LambdaでES6を使う
AWS Lambdaのnodeはv0.10.36なので、ちょっと古い。
ES6(ES2015)を実行するにはbabelで事前にコンパイルしておく必要がある。
babel-registerで逐次実行しようとしたらsyntax errorになった。もちろんローカルのnode 0.10では動いているんだけどどうして動かないのかわからない。require-hookがLambdaでは効かないようになっているのかもしれない。
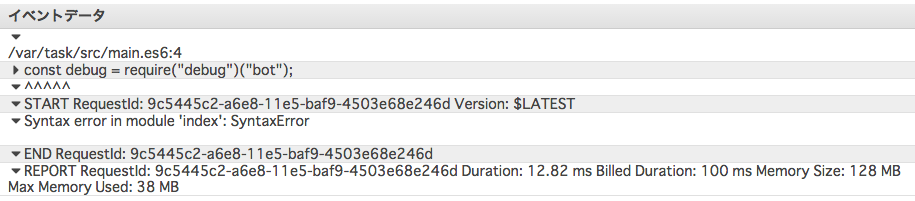
事前にsrc/以下をbabelでES5に変換してからzipで固めた。
% babel src/ --out-dir dist/ --source-maps inline
% zip -r bundle.zip index.js .env dist/ node_modules/
node_modules/ の中に実行に必要ないモジュールもたくさん混じってしまっているが、面倒なので全部まとめてbundle.zipに固めてしまった。npmが436個もあるけど11MB程度におさまったのでまあいいや。
ローカルで実験する
このtwitter botはAWSの機能は何も使っていないので、ローカルでも動く。
AWS Lambdaで実行された時はindex.jsがrequireされてそこからexportされてるhandlerメソッドが呼ばれる。
ローカルでも同じような動作をするrun.jsを用意して、そこから実行した。
run.js
var index = require("./index");
index.handler();
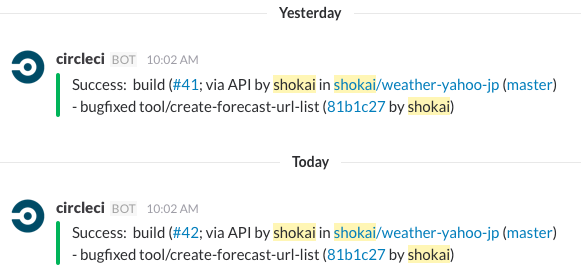
テスト
CircleCIでやってる
https://circleci.com/gh/shokai/neoyokohama-bot
ESLintかけてからmochaでクローラ等のモジュール毎のテストもやって、
一応buildしてzip作ってdry runまで
test:
override:
- npm run test
- npm run build
- npm run zip
- DRY=true npm start
AWS Lambdaに環境変数を渡す
twitterへの投稿には
twitter npmを使った。
OAuthのaccess tokenが必要だが、こういうのはgitリポジトリにコミットしたくないので環境変数で渡したい。
でもAWS Lambdaには環境変数を渡す機能がないので、
dotenv npmを使った。dotenvは.envファイルに書いた環境変数をloadできるので、.envファイルをzipに含めるようにした。
serverlessもdotenv使ってる。
require("dotenv").load({silent: true});
import Twitter from "twitter";
const client = new Twitter({
consumer_key: process.env.CONSUMER_KEY,
consumer_secret: process.env.CONSUMER_SECRET,
access_token_key: process.env.ACCESS_TOKEN_KEY,
access_token_secret: process.env.ACCESS_TOKEN_SECRET
});
なおdotenvはloadしたファイルの中でしかprocess.envが上書きされないっぽい。プログラムの頭でやっても効果ない。
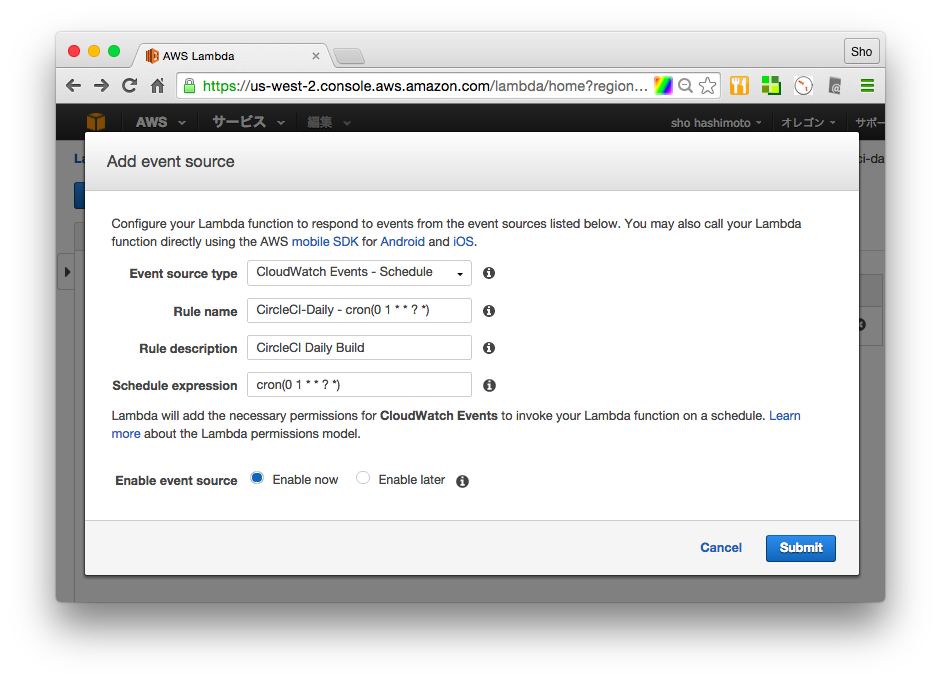
AWS Lambdaを定期的に実行する
ここまででだいたいスクリプトができたので、あとは毎朝実行するように設定する。
event sourceにscheduled eventを追加してcrontabのような記法で書く。
タイムゾーンがUTCなので、イギリスだから日本から9時間時差がある。毎日23時(日本の8時)に実行するようにした。
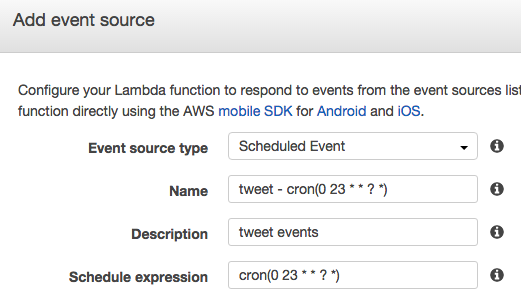
scheduled eventは英語版のドキュメントにのみ説明されている。日本語ドキュメントだと項目丸ごと無いのでしばらく困惑した。
Using AWS Lambda with Scheduled Events – AWS Lambda
crontabっぽいけど末尾にyearがある。
cron(Minutes Hours Day-of-month Month Day-of-week Year)
タイムゾーンを日本に設定する
スクレイピングしてきたイベントのリストから今日開催されるものを判定して抜き出す必要があるので、タイムゾーンを日本時間に設定したほうが計算しやすい。
Herokuでは環境変数TZを上書きしてやってたけどAWS Lambdaには環境変数を設定する機能が無い・・・ので、index.jsの冒頭で設定してしまう事にした。
process.env.TZ = "Asia/Tokyo";
これ以降はDateがちゃんと比較できる
Date.prototype.isToday = function(){
const today = new Date();
return this.getYear() === today.getYear() &&
this.getMonth() === today.getMonth() &&
this.getDate() === today.getDate();
};
やっぱserverless使おうかな
気温もtweetさせたいんだけど、前日との差をtweetしたほうがいいのでSimpleDBか何かに書き込みたい。なのでやっぱりserverless使ったほうが良さそうな気がしている。
あと、in_reply_to_status_idを使って連続tweetしてるんだけど処理が速すぎてtwitterに認識してもらえない。
間に数秒ディレイを入れたら認識されたけど、それではlambdaっぽくないので2つのlambda functionに分けてscheudled eventも1分ずらしてDBで最後のstatus_idを受け渡すかー、それならなおのことserverless使ったほうが良さそうだなとか思った。イベントソースが複数あってそれをGUIでポチポチやっていくのは混乱しそうなので全部コードでやりたい。
混雑度予想と開場時間もほしい。