9月202014
0
最初、Qでなぜかcatchでエラーが捕まえられないぞ?と書いていたけど、require(‘q’).Promiseを使うんだと教えてもらった。ありがとうございます。
—
色々なNodeのライブラリがそれぞれで好きなPromiseライブラリ使ってるけど、それらのライブラリ達をいっしょにアプリ内で混ぜてつなげても大丈夫なのか?ちゃんと相互にthenでチェインしたりエラー捕まえたりできるのか?
という事と、async.eachSeriesのようにURLのリストを1つずつ順番に処理完了するのを待ちながら処理していくのはPromiseでどうやって書くのかな?
というのが気になっていたのでちょっと調べた。
勉強用リポジトリ
https://github.com/shokai/promise-study
環境
node v0.10.29 + coffee-script v1.8.0なのでまだPromiseが標準ライブラリに入ってないNode環境
試したPromiseライブラリ
このへんが有名そうだったのでREADMEやサンプルなどを読んで、試した。でもdeferredはインタフェースがthenableじゃないっぽかったのですぐあきらめた。
結論
es6-promiseとbluebirdとQを混ぜこぜでthen/catchでチェインさせてもちゃんと動いた。then/catchしたいだけならes6-promise使って、
async.jsでやるような高機能な並列・並行処理の制御がしたければbluebirdやQに付いている便利な関数を使えばいいと思う。
試したコード
## いろいろなPromiseライブラリを使ってみる
{Promise} = require 'es6-promise'
# {Promise} = require 'q'
# Promise = require 'bluebird'
checkOdd = (num) ->
return new Promise (resolve) ->
if typeof num isnt 'number'
throw new Error "#{num} is not number"
resolve num % 2 is 1
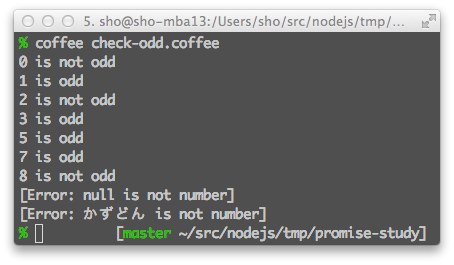
for i in [0,1,2,3,null,5,"かずどん",7,8]
do (i) ->
checkOdd i
.then (res) ->
if res
console.log "#{i} is odd"
else
console.log "#{i} is not odd"
.catch (err) ->
console.error err
実行結果
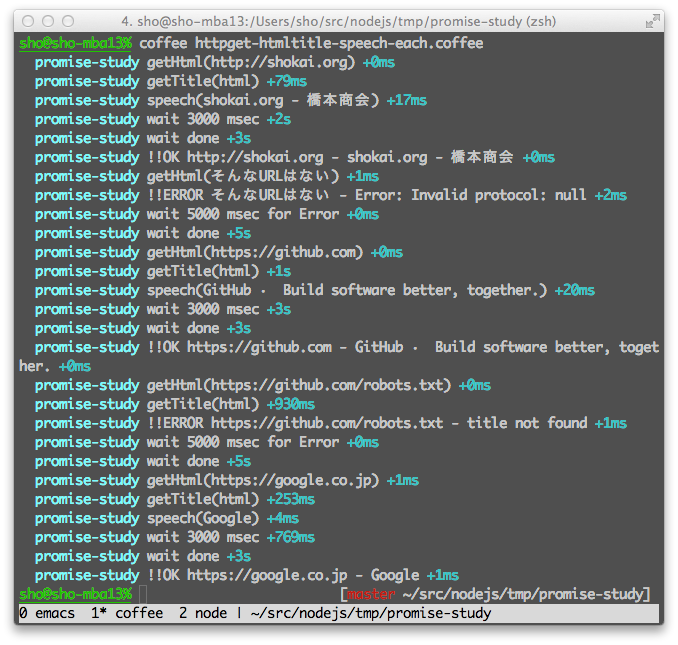
色々なPromiseライブラリをつなげる、1つずつ処理する
HTTP Getして、HTMLからtitleを取り出して、それをmacのsayコマンドで読む。という3つのPromiseをそれぞれ別々のPromiseライブラリで作る。
そして3つ繋げて1セットの処理として、URLリストを順番に処理していく。
RSSを順番に見ていくクローラー的な処理を想定していて、1つ終わったら3秒待ってから次のURLを見に行くようにした。
試しに書いてみたコード
ちなみにURLリストを全部同時に処理するversionもある
下の方でBluebird.eachを使って1つずつURLを処理していく。
thenのチェインが最後まで走ったら3秒待ってから次のURLを処理するし、どこか途中でエラーが起きたらcatchして5秒待って次のURLの処理に行く。
とにかく同時に複数のHTTPリクエストは送らない。
こういうのをasync.eachSeriesで書くとけっこう頭が疲れるコードになると思うけどPromise使ったらすんなり書けた。
es6-promiseとbluebirdとQを混ぜて使っているけどちゃんと動いた。
## HTMLを(1つずつ)取得してtitleを取り出してsayで読み上げる
## いろいろなPromiseライブラリを混ぜて使ってみる
## HTTPリクエストするのは3000 msecごと
## 途中でエラーがあったら5000 msec待ってから、次のHTTPリクエストする
request = require 'request'
cheerio = require 'cheerio'
{exec} = require 'child_process'
process.env.DEBUG ||= '*'
debug = require('debug')('promise-study')
{Promise} = require 'es6-promise'
Q = require('q')
Bluebird = require 'bluebird'
urls = [
'http://shokai.org'
'そんなURLはない' # URLじゃない文字列。requestの例外を発生させるため
'https://github.com'
'https://github.com/robots.txt' # HTMLが返ってこないURL。titleタグ取得のエラーを起こすため
'https://google.co.jp'
]
# HTML本文を取得するPromise
# URLが間違っていたりすると失敗する
getHtml = (url) ->
debug "getHtml(#{url})"
return new Q.Promise (resolve, reject) -> # Qを使う
request url, (err, res, body) ->
if err or res.statusCode isnt 200
return reject(err or "statusCode: #{res.statusCode}")
resolve body
# HTMLからタイトルを取得するPromise
# HTMLじゃなければ失敗する
getTitle = (html) ->
debug "getTitle(html)"
return new Bluebird (resolve, reject) -> # Bluebirdを使う
$ = cheerio.load html
if title = $('title').text()
return resolve title
reject 'title not found'
# 音声読み上げするPromise
speech = (txt) ->
debug "speech(#{txt})"
return new Promise (resolve, reject) -> # es6-promiseを使う
exec "say #{txt}", (err, stdout, stderr) ->
return reject(txt) if err
resolve(txt)
# URLリストをBluebird.eachで1つずつ処理する
Bluebird.each urls, (url) ->
getHtml url
.then getTitle
.then speech
.then (title) ->
return new Q.Promise (resolve) -> # Qを使う
debug "wait 3000 msec"
# 3秒待ってから次のURLの処理へ
setTimeout ->
debug "wait done"
debug "!!OK #{url} - #{title}"
resolve()
, 3000
.catch (err) ->
return new Promise (resolve, reject) -> # es6-promiseを使う
debug "!!ERROR #{url} - #{err}"
debug "wait 5000 msec for Error"
# どこかでエラーあったら5秒待つ
setTimeout ->
debug "wait done"
resolve()
, 5000
実行結果
ちゃんと3秒/5秒待って次、と順番に処理できている。requestにURLじゃない文字列を渡した時の例外も、try catch書かずにpromiseのcatchで捕捉できている。