wordのOCR機能がCOM APIから使えるとの事だったので試した。
まちみのな::C#で文字認識を行うとCodeProject: OCR with Microsoft? Office. Free source code and programming helpを参考にした、というかほぼそのままで、UIを付けただけ。
日本語OCRは商用の物しか見つからなくて、クセロReaderに入ってるとかどうやってか自分で作ってる人もいるけど、高嶺の花だった。英語はオープンソースプロジェクトがいくつかあるのになあ・・・
できたもの。
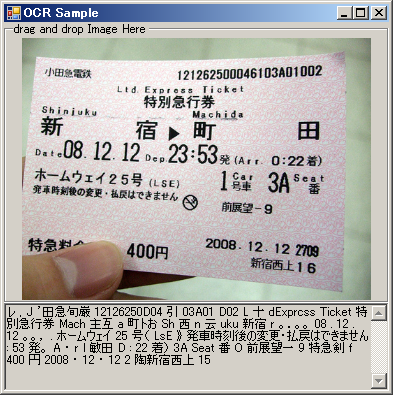
画像をドラッグアンドドロップするとOCR発動、文字を読み取る。この画質の写真でも相当間違える。
■作ったサンプル
shokai / OCR C# Sample / overview — bitbucket.org (VS2008 C#.NET用)
右上のDownloadからzipでもダウンロードできます
wordについてるDocument Image Writerがインストールされているマシンなら動くと思う。
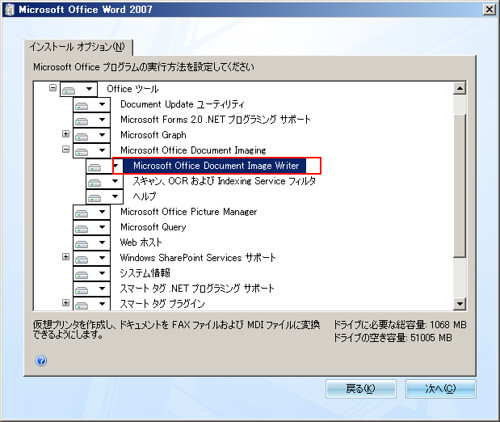
■Microsoft Office Document Image Writerのセットアップ
Word2007には入っていたのでCDからインストールしなおした。普通にインストールするとチェックが外れててインストールされない。
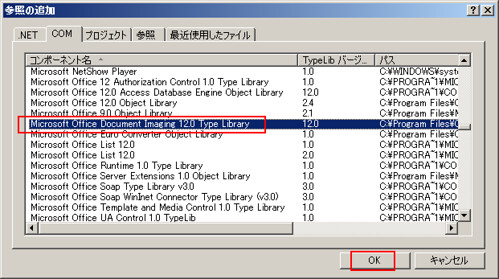
VisualStudioのプロジェクトの「参照の追加」で「Microsoft Office Document Imaging 12.0 Type Library」があるので読み込むと使える
2007で12.0なので、昔のwordにも入っていそう
■使う
参照の追加ができていればこれだけでOCRが動いて、テキストが読み取れる。
OcrSampleForm.cs
MODI.Document doc = new MODI.Document();
doc.Create(filename); // ファイル名を指定
doc.OCR(MODI.MiLANGUAGES.miLANG_JAPANESE, false, false); // 日本語指定
foreach (MODI.Image img in doc.Images) // 複数ページあるファイルを順に読む
{
MODI.Layout layout = img.Layout;
textBoxResult.Text = layout.Text; // テキストボックスに表示
}
フォント名も取れるらしい。
font名が取れるという事はwindowsにインストールされているfontに依存しているのかな?
たくさんインストールしてあれば認識率が上がるかも。
Monoでは動かせなかった。ole32.dllでエラーが出るが、同じディレクトリに置いたりしても駄目だった。サーバーで動かせれば夢が広がるだが
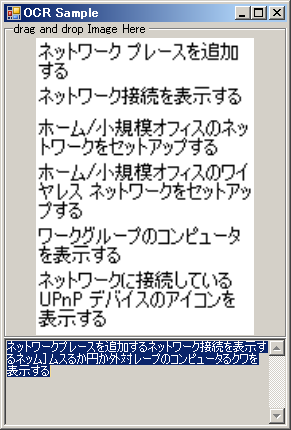
■色々な画像を読み込ませる
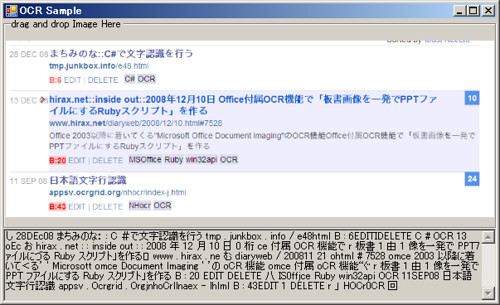
スクリーンショットはよく読める。
印刷物の縦書きが自動認識された

まずまず
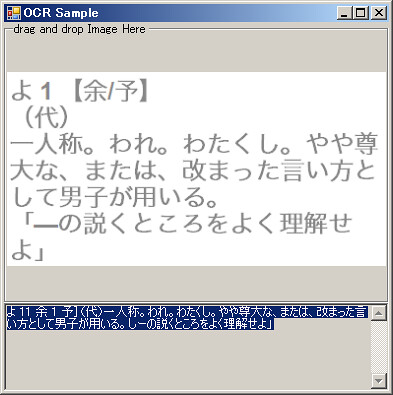
まあまあ
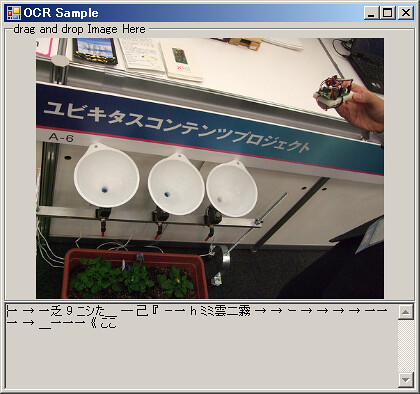
全然駄目
切り抜いても駄目
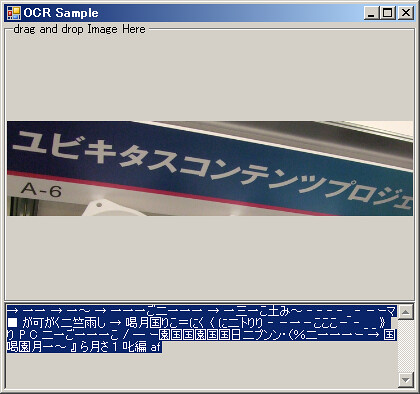
softbankだけ認識した
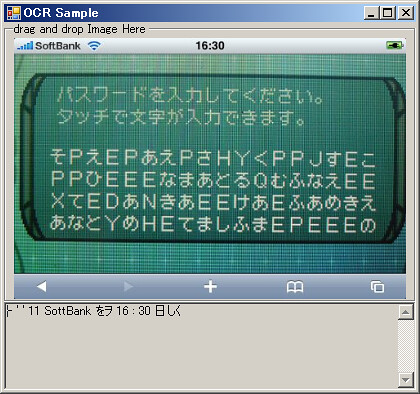
これを使ってwebcam頭に付けて町中歩き回って、認識した文字をtwitterにpostしまくる、とかはうまくいかないと思う。
fontが合致しないと認識しないみたいなので、看板のfontが全部手に入ったらできるかも。
この精度でも検索ワード代わりにはなりそうなので、手持ちの写真のExifに全部OCRでテキストデータを付けるとかしようかな。
Flickrでやってもいいけどタグは完全一致だから検索用には向いてない。自前でDB作るとか。