11月 182015
ドイツ語などのヨーロッパの言語ではたまにåとかöみたいな文字が使われていて、UTF-8とかじゃなくISO-8859-1などの文字コードが使われている事があるらしい。
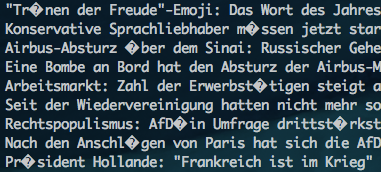
ドイツのspiegelという雑誌のRSSがちょうどISO-8859-1で、hubot-rss-readerで読むとところどころ文字化けするようになっていた。
こんな感じ
Node.jsでfeedを読む
feedの取得にはrequest、parseにfeedparserを使うのが多分普通なのだが、この2つはpipeでつないで使うようになっている。で、最初は
Node.jsで文字コードの自動判別と自動変換 – Qiita
のようにjschardetで文字コードを判別して、iconvで変換してみた。でもrequest→feedparserがstreamなので少しずつchunkで送られてきて、日本語のマルチバイト文字の途中で区切りが来たりする事がある。そのchunkを1つずつjschardetにかけてしまうと全然違う文字コードが出てきたりする事があって良くない。
冷製になって考えたら、XMLなんだから頭に<?xml encoding=”ISO-8859-1″とか書いてあるのを読んでUTF-8じゃなかったら変換するstreamを作ればいい事に気づいた。
streamでXMLを食わせるとUTF-8に変換して吐き出すstream
というわけで、まずXMLのencoding attributeを読んで必要があればUTF-8に変換するstreamを返す関数を作るcharset-convert-stream.coffee
stream = require 'stream'
Iconv = require('iconv').Iconv
module.exports = ->
iconv = null
charsetConvertStream = stream.Transform()
charsetConvertStream._transform = (chunk, enc, next) ->
if m = chunk.toString().match /<\?xml[^>]* encoding=['"]([^'"]+)['"]/
charset = m[1]
if charset.toUpperCase() isnt 'UTF-8'
iconv = new Iconv charset, 'UTF-8//TRANSLIT//IGNORE'
if iconv?
@push iconv.convert(chunk)
else
@push chunk
next()
return charsetConvertStream
ドイツ語のfeedを読む
requestのon “response”からpipeでcharsetConvertStreamを通してfeedparserに繋ぐと、いい感じにUTF-8にエンコードされて出てくる。FeedParser = require 'feedparser'
request = require 'request'
charsetConvertStream = require './charset-convert-stream'
feedparser = new FeedParser
req = request
uri: process.argv[2] or 'http://www.spiegel.de/schlagzeilen/tops/index.rss'
timeout: 10000
encoding: null # null指定でrequestが勝手にエンコードしなくなる
headers:
'User-Agent': 'test-feed-reader'
req.on 'error', (err) ->
console.error err
req.on 'response', (res) ->
if res.statusCode isnt 200
return console.error "statusCode: #{res.statusCode}"
this
.pipe charsetConvertStream()
.pipe feedparser
feedparser.on 'error', (err) ->
console.error err
feedparser.on 'data', (entry) -> # エントリーが1件ずつイベントで出てくる
console.log entry.title
console.log entry.summary or entry.description
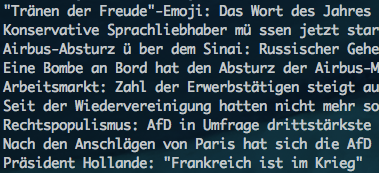
文字化けなくなった
ここまでやって気づいたんだけど、 feedparser.meta[‘#xml’].encoding にエンコード情報が入っているのでこれを使ってtitleやdescriptionなど必要な所だけ取り出してからiconv.convertしても良かったかも・・