6月162015
0


HerokuのHubotを寝させる
無料で使うには1日6時間寝かせないとならないのでHeroku | Heroku’s Free (as in beer) Dynos
dashboard.heroku.comからaddonにProcess Schedulerを追加して6時間寝させる。
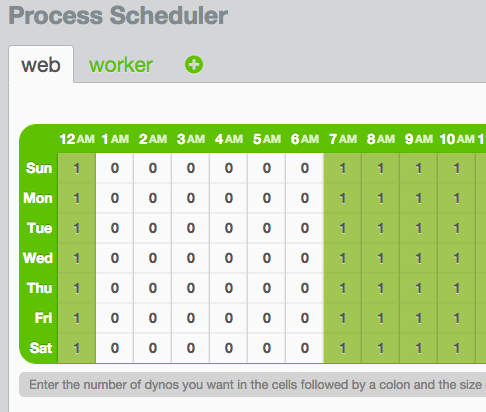
参考:HerokuでHubotを指定の時間に寝かせる – はらへり日記
寝る前に報告させる
寝る前に「寝ます」とか「寝ましょう」とか言ってくれた方が安心感がある。herokuはプロセスの終了時にSIGTERMを投げてくるので、それを受ければいい。
nodeだとprocess.on(‘SIGTERM’, function(){ });でキャッチできるはずだけどHubotではできなかった。ソースをよく見たらbin/hubotが先にSIGTERMにイベントを登録して、その中でexitしていた。なのでSIGTERMイベントを上書きした。
module.exports = (robot) ->
## 起きた時、slack-adapterがつながるのを待って通知
cid = setInterval ->
return if typeof robot?.send isnt 'function'
robot.send {room: "#general"}, "ガバリ"
clearInterval cid
, 1000
## 寝た時、通知してからexitする
on_sigterm = ->
robot.send {room: "#general"}, 'スヤリ'
setTimeout process.exit, 1000
if process._events.SIGTERM?
process._events.SIGTERM = on_sigterm
else
process.on 'SIGTERM', on_sigterm
processがイベント管理に使っているEventEmitterは先に登録したイベントが先に実行される。先にbin/hubotが登録したイベントを削除するにはイベント登録時にreturnされるidを使うしか無いので、仕方なく_eventsプロパティを直接書き換えた。
hubotの仕様が変わった時に挙動がおかしくなるかもしれないけど、例えばsocket.ioがhttp.serverに/sockets/socket.io.jsを登録する処理とかでも_eventsの順序入れ替えをやっているし、まあしょうがない。EventEmitterとはそういう物だと思うしかない。
先に登録されていなければ普通にonで登録する。
本当は上書きじゃなくて先に実行されるようにしようかと思ったけど、eventemitterは登録されているコールバックが複数なら配列で持ち、1つなら配列ではなく関数を直接持つので、なんだか面倒になって上書きにした。